Planual rules for source data in Anaplan Data Orchestrator.
8.01-01 Create a module in the model that includes only the data you want to bring into Data Orchestrator
When using Anaplan as a source of data, create a module in the model that includes only the data you want to bring into Data Orchestrator.
Data Orchestrator will copy all the data from the module into a source dataset, including calculated and aggregated data points.
8.01-02 Use the correct column data types
Source data from all non-structured data sources (such as local files and S3) all have columns as strings. Create a transform to cast these to the correct type.
This approach makes subsequent use of the data in transformations easier as the functions and transforms that can be applied are dependent on column data types, such as aggregations.
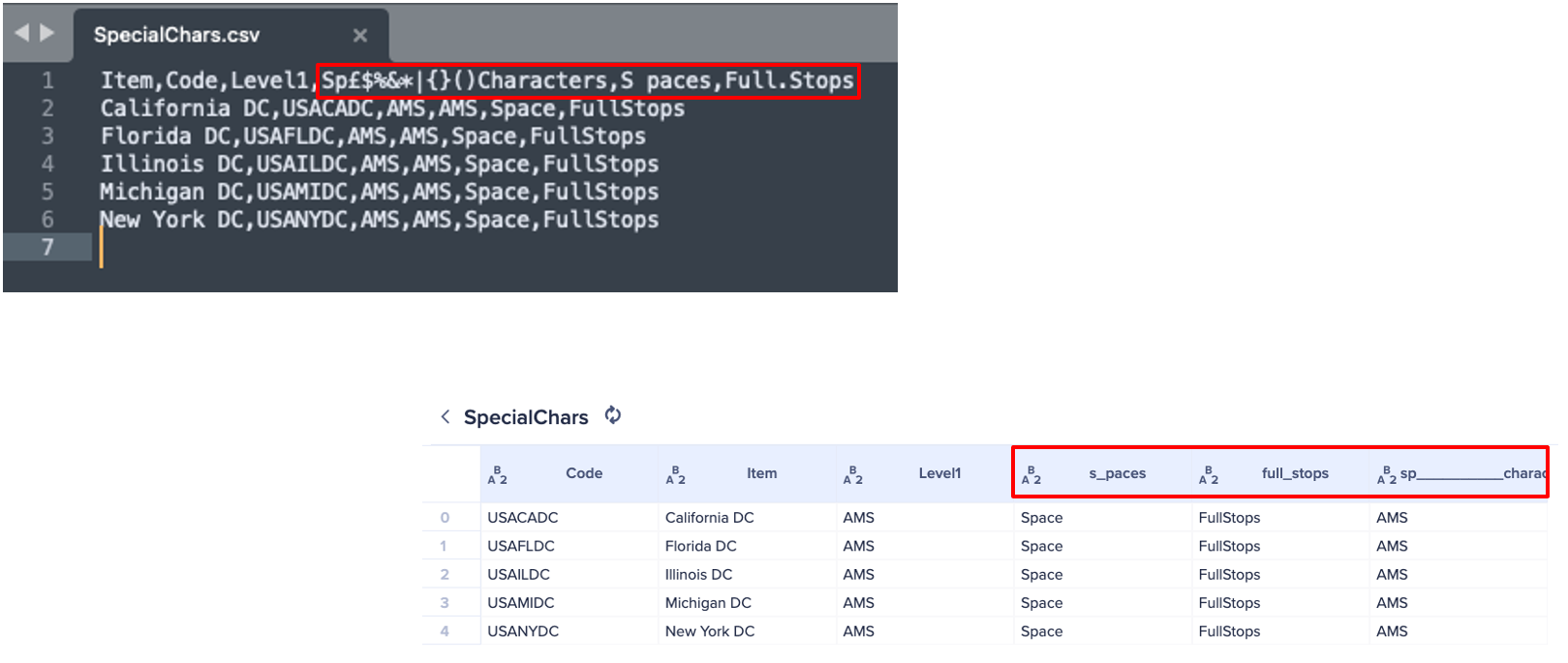
8.01-03 Follow the correct column naming convention
CSV and text files must have the column names in the first row followed by data from row 2 onwards. Column names should be unique and not include special characters, such as spaces and dots. Underscore characters will replace any special characters.
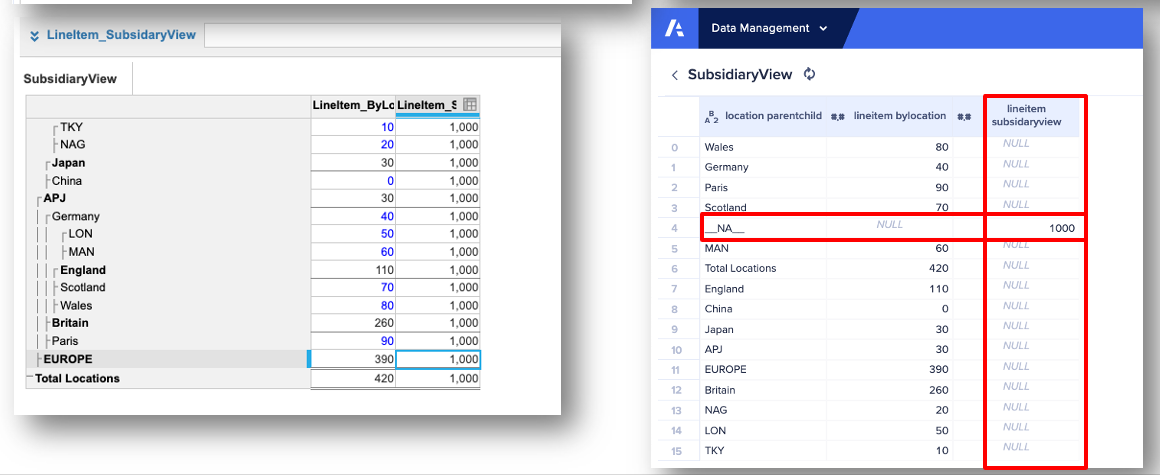
8.01-04 Avoid extracting data from modules with subsidiary views
Don't source the data from modules with subsidiary views when you extract module data from Anaplan into Data Orchestrator.
This results in a complex data structure with columns that aren't relevant to specific line items. It's also not possible to limit the scope of the data that's been extracted using a saved view.
Create a module in the model that contains only the data that's needed for Data Orchestrator.
relatedToRule
8.01-05 Avoid multiple transformation chains referencing the same source data
Rather than have multiple transformation chains reference a source dataset directly, create a single transformation from the source dataset and have this serve as the input for all subsequent transformations and links.
This makes it easier to replace the source dataset or handle changes in structure. It also minimizes the impact on downstream transformations and/or the need to remap downstream transformations.
8.01-06 Be mindful of source system delete behavior
Some systems, Salesforce for example, don't immediately purge a record, even when it is deleted from the recycle bin.
According to Salesforce documentation, "When records are purged from the recycle bin, they might still be visible through API until they are completely purged from the organization. Users with View All Data and API access can check for records in this state by using Export All in Data Loader, and filtering on isDeleted = True."
It seems that if you wait between deleting the row and resyncing using append mode, the row won't be added to the sync.
Additionally, you can observe that the final table contains a column isDeleted that indicates whether the row has been deleted.
Add a transformation with a filter into Data Orchestrator to remove the rows that have been deleted.
8.01-07 Understand factors that can impact connector performance
Connector performance varies significantly based on several factors:
- The connector itself. The interface technology used for the data source impacts the rate at which data can be extracted from the source systems into Data Orchestrator. For example, the SAP OData connector is limited by governors within SAP designed to prevent external applications from impacting performance.
- The volume of data. There is a reasonably high fixed cost in starting a sync for a data extract, so we see that the rows per second increase as the number of rows increases - up to a maximum. The number of columns in the rows has less impact on performance.
- The location of the data. Extract of data from a source system into Data Orchestrator is impacted by the location of the source data and where Data Orchestrator has been provisioned. If the source is in the Cloud, then having the source in the same region and ideally the same physical data center will improve the performance of data transfer versus the data residing on the other side of the world. There are similar considerations for on prem data sources, with the additional impact of the customer's network topology.

