
Planual rules for source data in Anaplan Data Orchestrator.
8.01-01 Data Orchestrator に取り込みたいデータのみを含むモジュールをモデル内に作成する
Anaplan をデータ ソースとして使用する場合は、Data Orchestrator に取り込みたいデータのみを含むモジュールをモデル内に作成します。
Data Orchestrator によって、計算および集計されるデータ ポイントを含むすべてのデータが、そのモジュールからソース データセットにコピーされます。
8.01-02 正しい列データ型を使用する
すべての非構造化データ ソース (ローカル ファイルや S3 など) のソース データには、すべてに文字列の列があります。これらを正しい型にキャストするための変換を作成します。
このアプローチでは、適用できる関数と変換が集計などの列データ型に依存するため、変換におけるその後のデータの使用が容易になります。
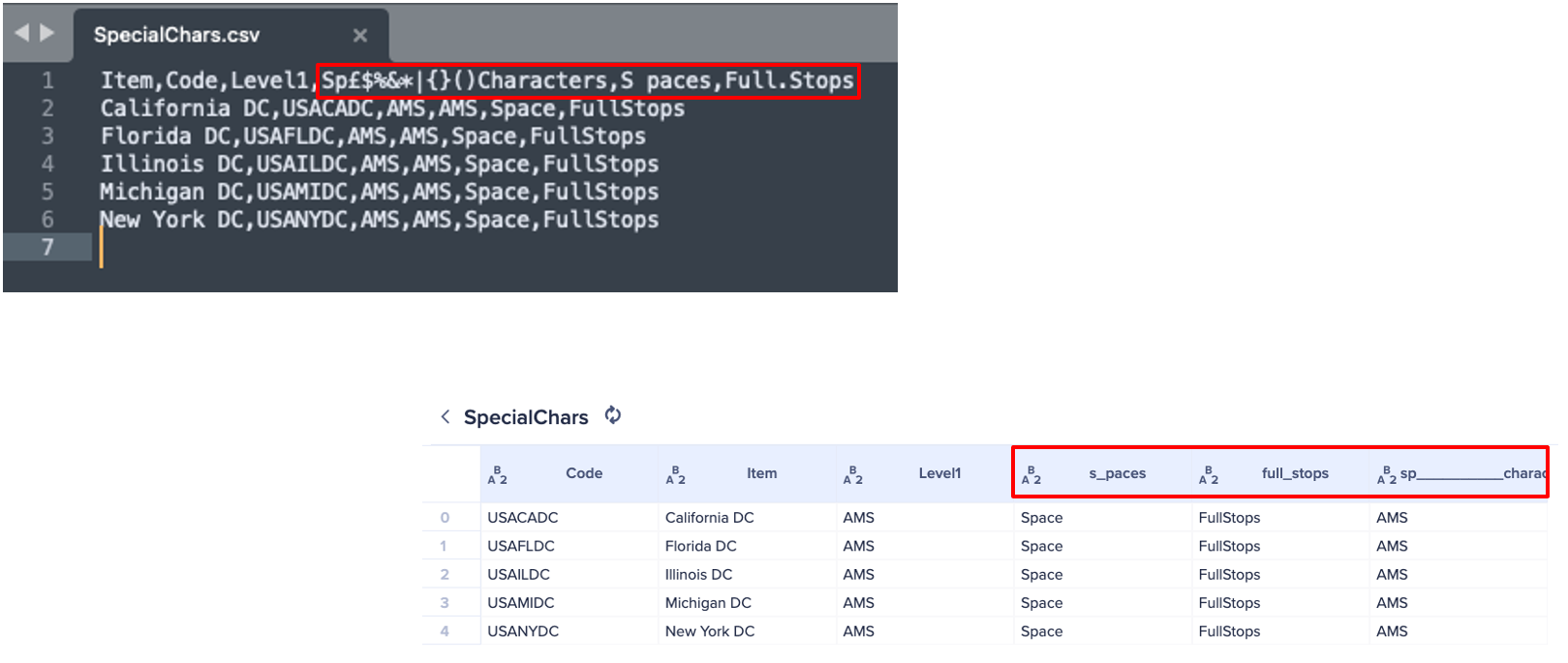
8.01-03 Follow the correct column naming convention
CSV and text files must have the column names in the first row followed by data from row 2 onwards. Column names should be unique and not include special characters, such as spaces and dots. Underscore characters will replace any special characters.
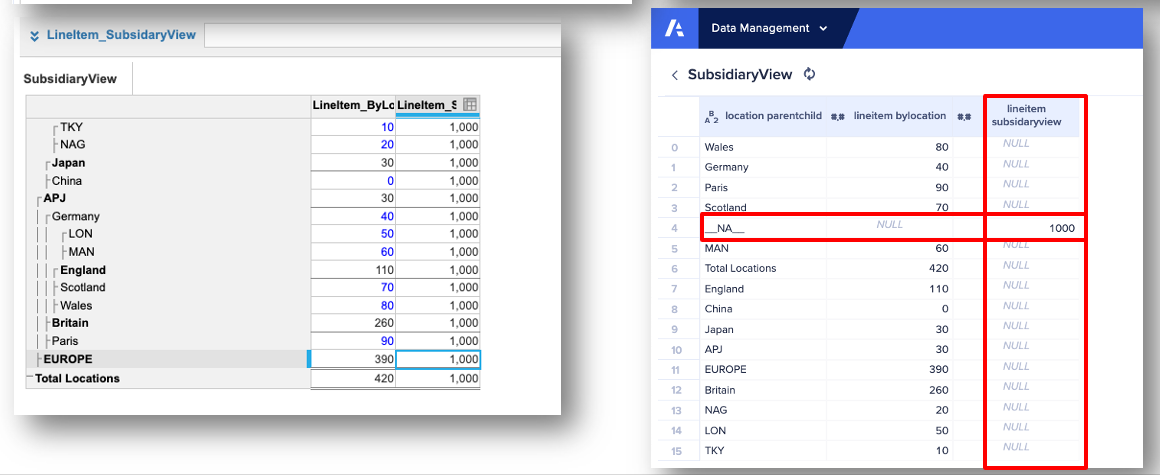
8.01-04 補助ビューがあるモジュールからデータを抽出しないようにする
Anaplan からモジュール データを Data Orchestrator に抽出する際に、補助ビューがあるモジュールからデータを取得しないでください。
これを行うと、特定のライン アイテムに関連しない列を含む複雑なデータ構造が生成されます。また、保存済みビューを使用して抽出されたデータの範囲を制限することもできません。
モデル内に、Data Orchestrator に必要なデータのみを含むモジュールを作成します。
relatedToRule
8.01-05 同じソース データを参照する複数の変換チェーンは避ける
複数の変換チェーンでソース データセットを直接参照するのではなく、ソース データセットから単一の変換を作成し、これを後続のすべての変換とリンクの入力として使用します。
これにより、ソース データセットの置き換えや構造の変更の処理が容易になります。下流の変換への影響や下流の変換を再マッピングする必要性も最小限に抑えられます。
8.01-06 ソース システムの削除動作に注意する
一部のシステム (Salesforce など) では、レコードがごみ箱から削除されてもすぐには消去されません。
Salesforce documentation によると、レコードがごみ箱から消去された場合、組織から完全に消去されるまで、レコードは API を通じて引き続き表示される可能性があります。全データ閲覧アクセス権と API アクセス権を持つユーザーは、データ ローダーの [Export All] を使用し、isDeleted = True でフィルタリングすることで、この状態のレコードを確認できます。
行を削除してから追加モードを使用して再同期するまで待機すると、行は同期に追加されないようです。
さらに、最終的なテーブルには、行が削除されているかどうかを示す isDeleted という列が含まれていることがわかります。
削除されている行を取り除くには、フィルターを使用した変換を Data Orchestrator に追加します。
8.01-07 コネクターのパフォーマンスに影響を与えかねない要因を理解する
コネクターのパフォーマンスは次のような複数の要因に大きく左右されます。
- コネクターそのもの:データ ソースに使用されるインターフェース テクノロジーは、ソース システムから Data Orchestrator にデータを抽出できる速度に影響します。たとえば、SAP OData コネクターは、外部アプリケーションがパフォーマンスに影響を与えないように設計された SAP 内のガバナーによって制限されています。
- データの量:データ抽出の同期を開始するにはかなり高い固定コストがかかるため、行数が増加すると、1 秒あたりの行数が最大値まで増加します。行内の列数はパフォーマンスにあまり影響しません。
- データの場所:ソース システムから Data Orchestrator へのデータの抽出は、ソース データの場所と Data Orchestrator がプロビジョニングされている場所に影響を受けます。ソースがクラウドにある場合、ソースを同じリージョン、理想的には物理的に同じデータ センターに置くことで、世界の反対側にあるデータと比べてデータ転送のパフォーマンスが向上します。オンプレミスのデータ ソースについても同様の考慮事項があり、顧客のネットワーク トポロジによる影響も加わります。

